This article is for IT and security professionals
FMI Works products are designed to run in the cloud and provide a seamlessly scalable solutions for any number of customers. This is built on a number of technologies, each of which contribute to this goal.
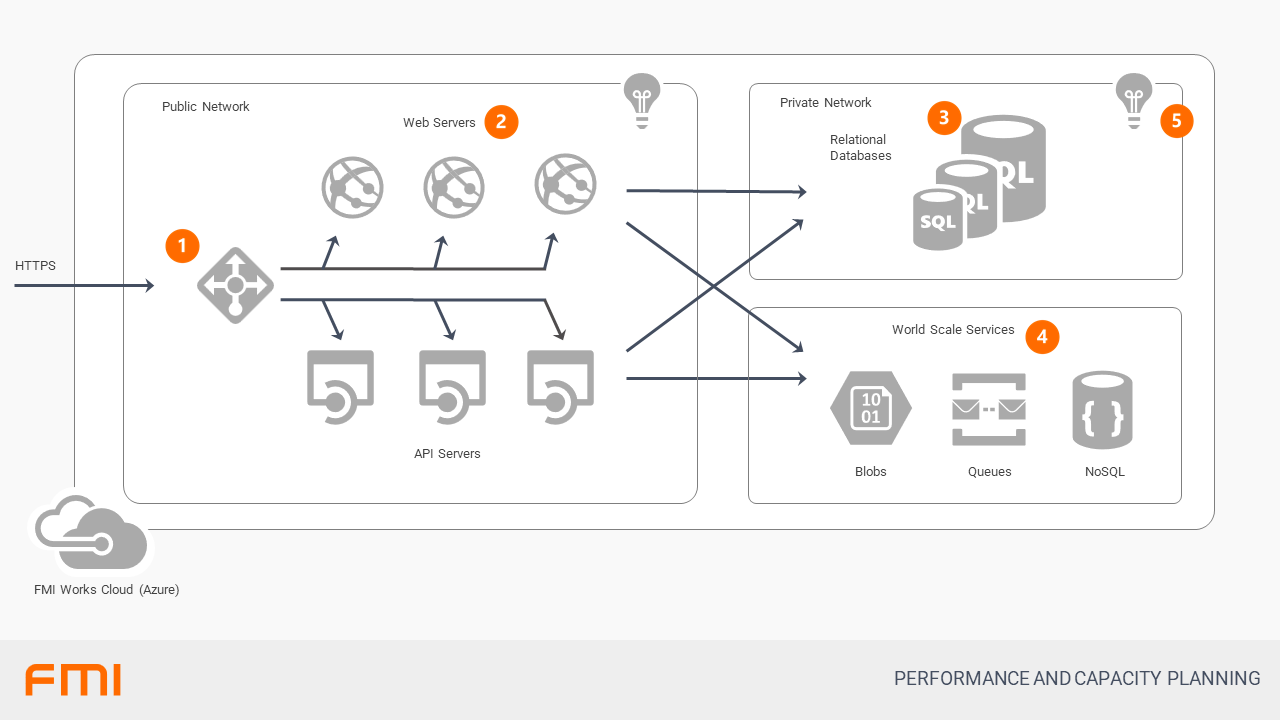
- FMI Works is delivered through a software-as-a-service (SaaS) model. Whether the client is a Web Application or a Mobile App, all requests for information come into the system as a HTTPS web requests. These requests are then sent to a load balancer, which dynamically shares the load amongst our back-end services.
- At the web application layer, the primary mechanism to enable large loads is through the elastic ability to Scale-Out to multiple machines that can each support the requests from clients. For example, additional server instances are added whenever the existing load exceeds 80% of capacity.
- Most data is stored in traditional relational databases. These are provisioned in a cluster for HA/DR and the primary mechanism for performance and scalability is the ability to scale-up the database servers.
- When practical, FMI also makes uses of technologies that have been designed for cloud-scale applications, such as blobs, queues and NoSQL data stores. There are portions of the system that can either easily be migrated to these technologies or that, because of size, require these technologies.
- Active monitoring of these solutions occurs constantly in our production environments, where alerts notify us when systems are slowing down.
- These alerts include web, API, database and related services.
- Alerts are triggered for degradation, not capacity, so a service that runs in 10ms normally will be alerted as a problem if it slows to even 30ms.
- The number of average and peak concurrent users for services is also reported.
Manual load-tested is periodically performed to determine the carrying capacity of the existing infrastructure and ensure that capacity plans are sufficient for future growth.
- Web pages and APIs are load tested with increasing loads until failure.
- Degradation of service is noted when the maximum wait for a standard call is 1 second.
- Unacceptable service is noted when the maximum wait exceeds 10 seconds.
- Scale-out and scale-up of services are tested to accommodate 100% more than peak capacity with no degradation of service.
- Contingency plans are created to ensure service levels can be met at any time given extrapolated customer growth over next 12 months.